Data transformations
Lecture 10
2025-04-10
Factor reorder
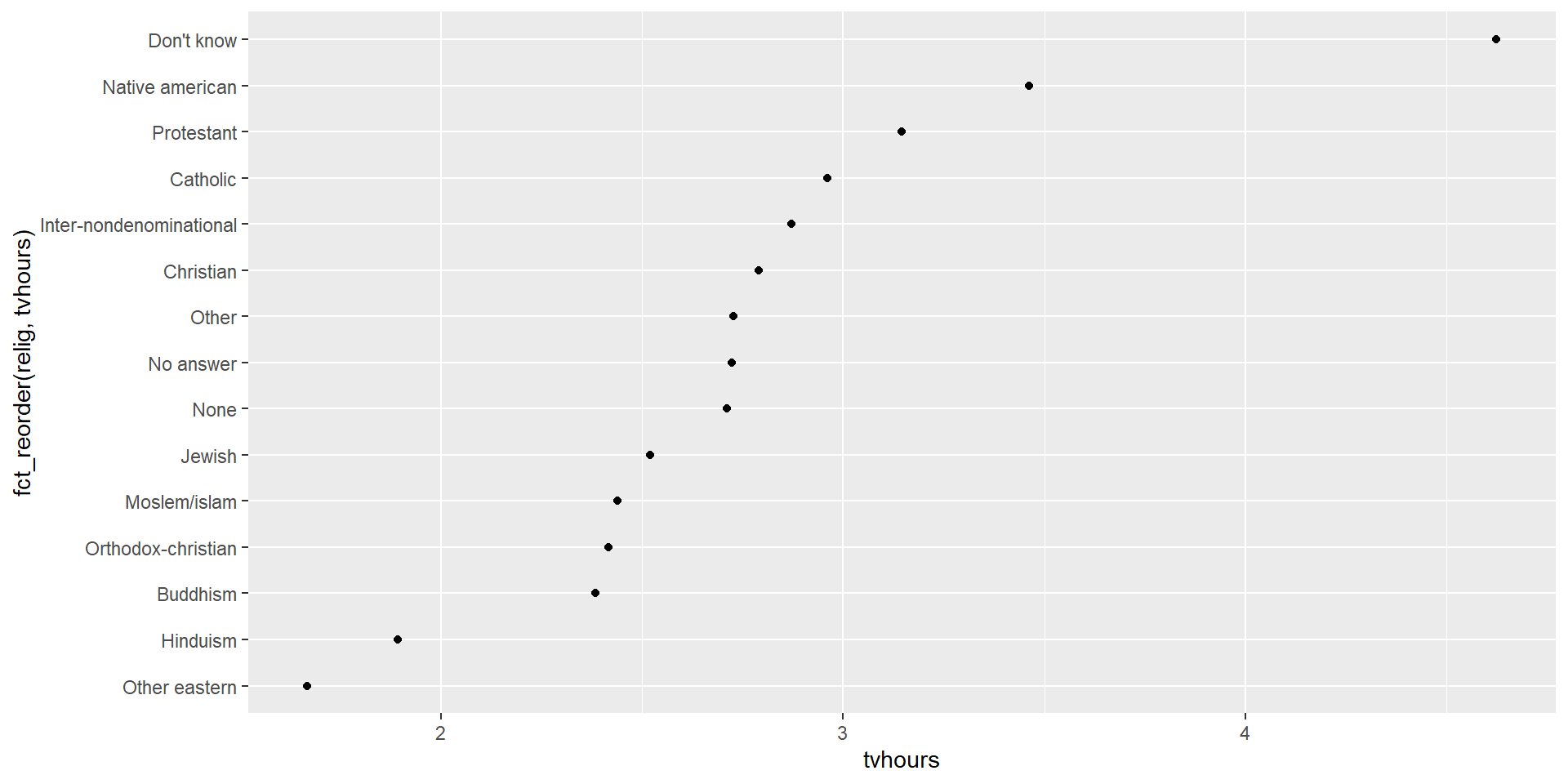
Imagine the following plot, what would you like to ameliorate it for

Factor reorder
It is hard to read this plot because there’s no overall pattern. We can improve it by reordering the levels of relig using fct_reorder(). fct_reorder() takes three arguments:
.f, the factor whose levels you want to modify..x, a numeric vector that you want to use to reorder the levels.- Optionally,
.fun, a function that’s used if there are mu
Factor reorder
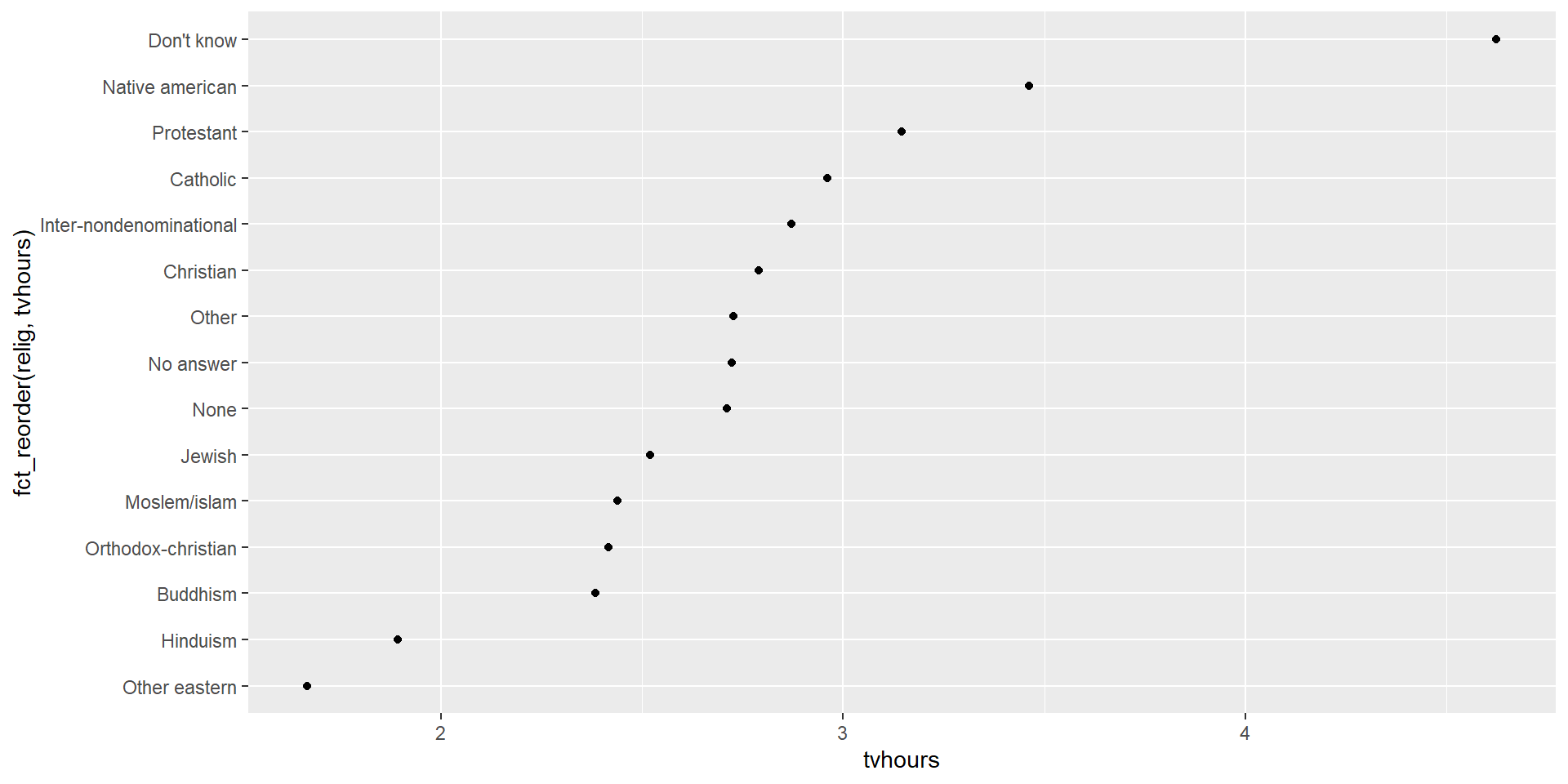
Factor relevel
Imagine the following plot, maybe you would like to have “Not applicable” not show up at the top of the graph.

Factor relevel
You can use fct_relevel(). It takes a factor, .f, and then any number of levels that you want to move to the front of the line.
