# Install necessary packages if not already installed
if(!require(tidyverse)) install.packages("tidyverse")
if(!require(rpart)) install.packages("rpart")
if(!require(rpart.plot)) install.packages("rpart.plot") # Install rpart.plot
if(!require(caret)) install.packages("caret")
if(!require(randomForest)) install.packages("randomForest")
if(!require(DiagrammeR)) install.packages("DiagrammeR")
# Load the libraries
library(tidyverse)
library(rpart)
library(rpart.plot) # Load rpart.plot
library(caret)
library(randomForest)
library(DiagrammeR) # Load DiagrammeRDecision Trees
Lecture 12
2025-04-17
A Simple Example
Imagine deciding whether to drink tea or coffee based on: - Time of day - Hours of sleep from last night
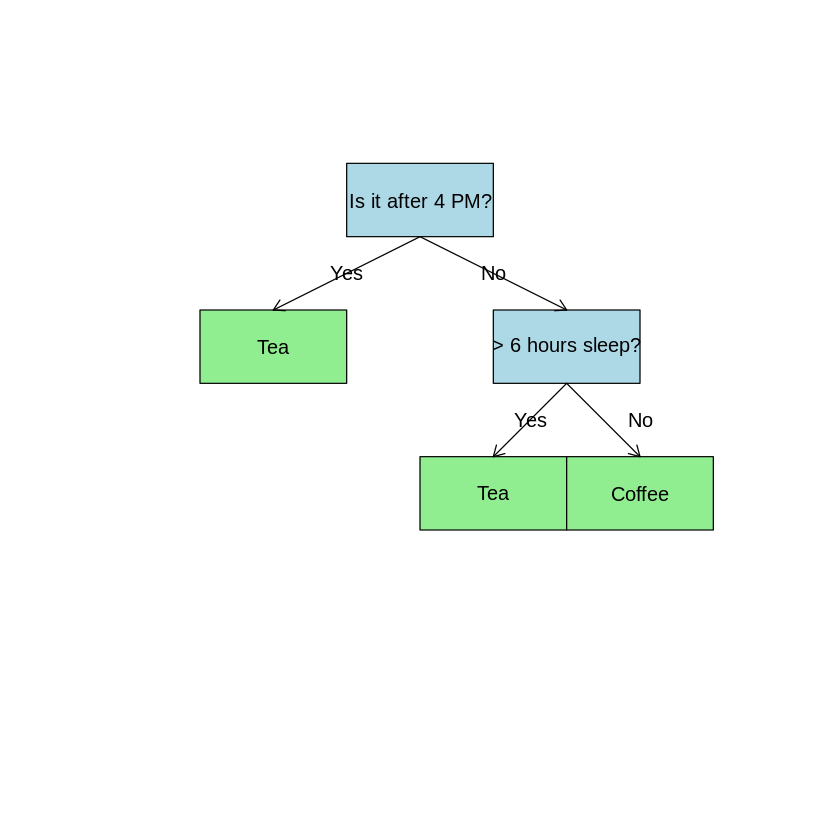
Simple decision tree example
Using Decision Trees with Data
In practice, we use tabular data where each row is evaluated through the tree:
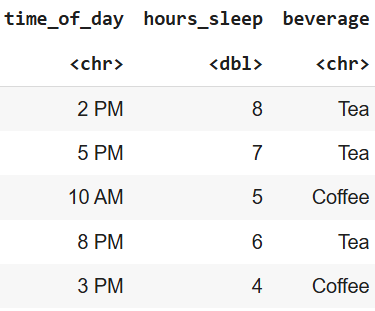
Tabular data example
Graphical View of a Decision Tree
Decision trees partition the feature space into regions:
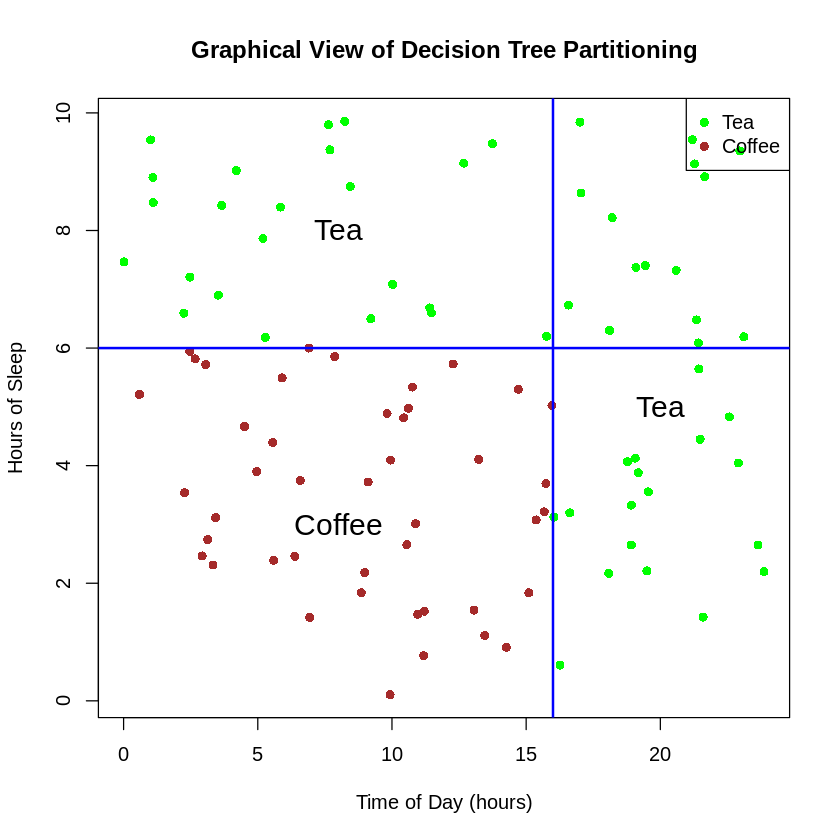
Graphical view of decision tree partitioning
Overfitting in Decision Trees
A fully grown tree might perfectly classify training data but perform poorly on new data:
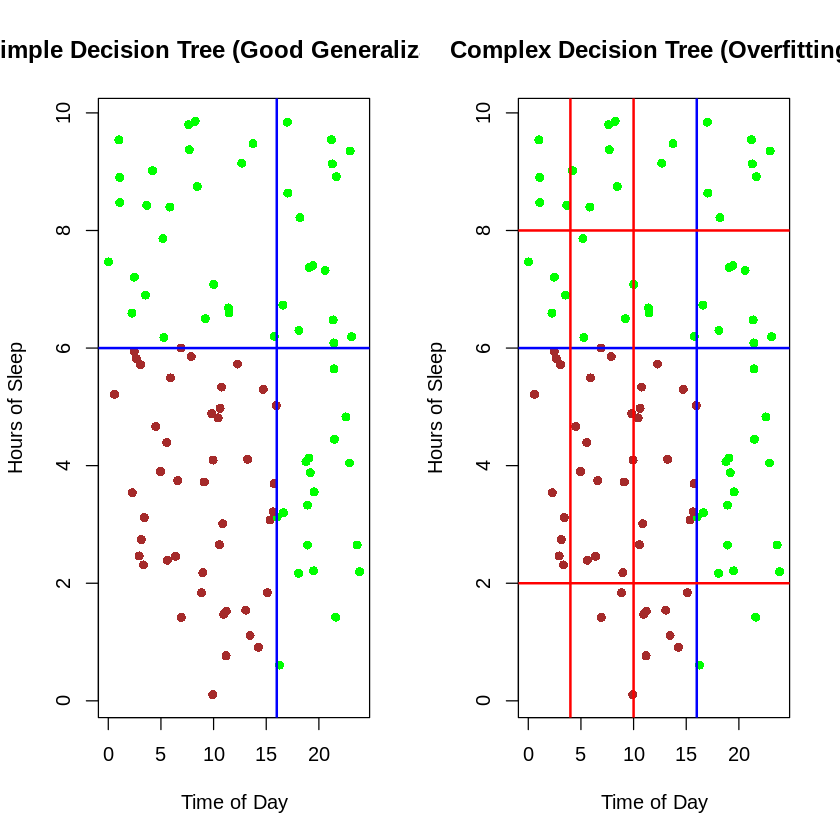
Comparison of simple vs. complex decision boundaries
Visualizing the Decision Tree
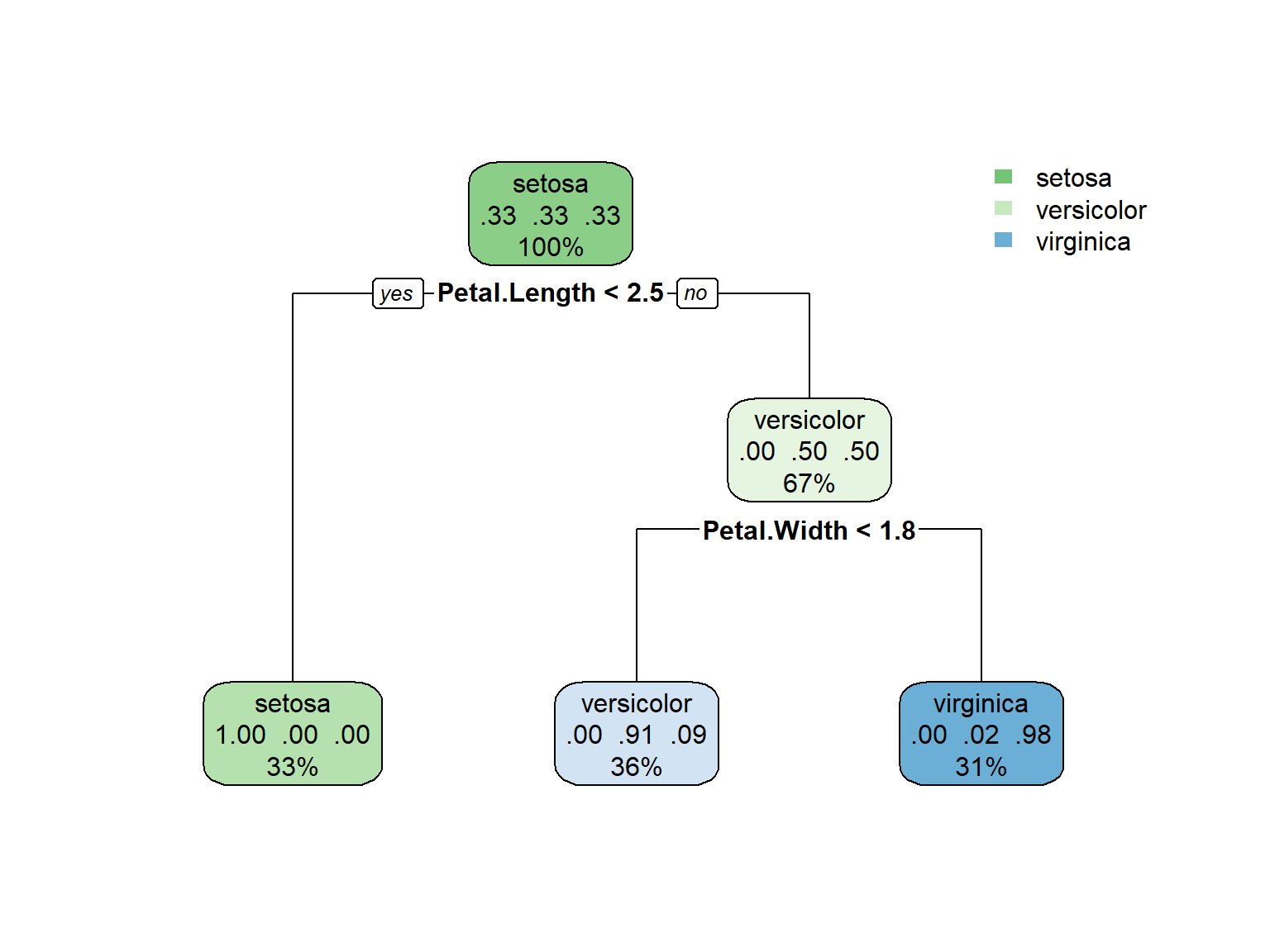
Training the Model
# Train a decision tree model
diabetes_tree <- rpart(Outcome ~ .,
data = train_data,
method = "class",
control = rpart.control(cp = 0.01)) # complexity parameter
# View the result
rpart.plot(diabetes_tree,
extra = 106,
box.palette = "RdBu",
fallen.leaves = TRUE,
main = "Diabetes Classification Decision Tree")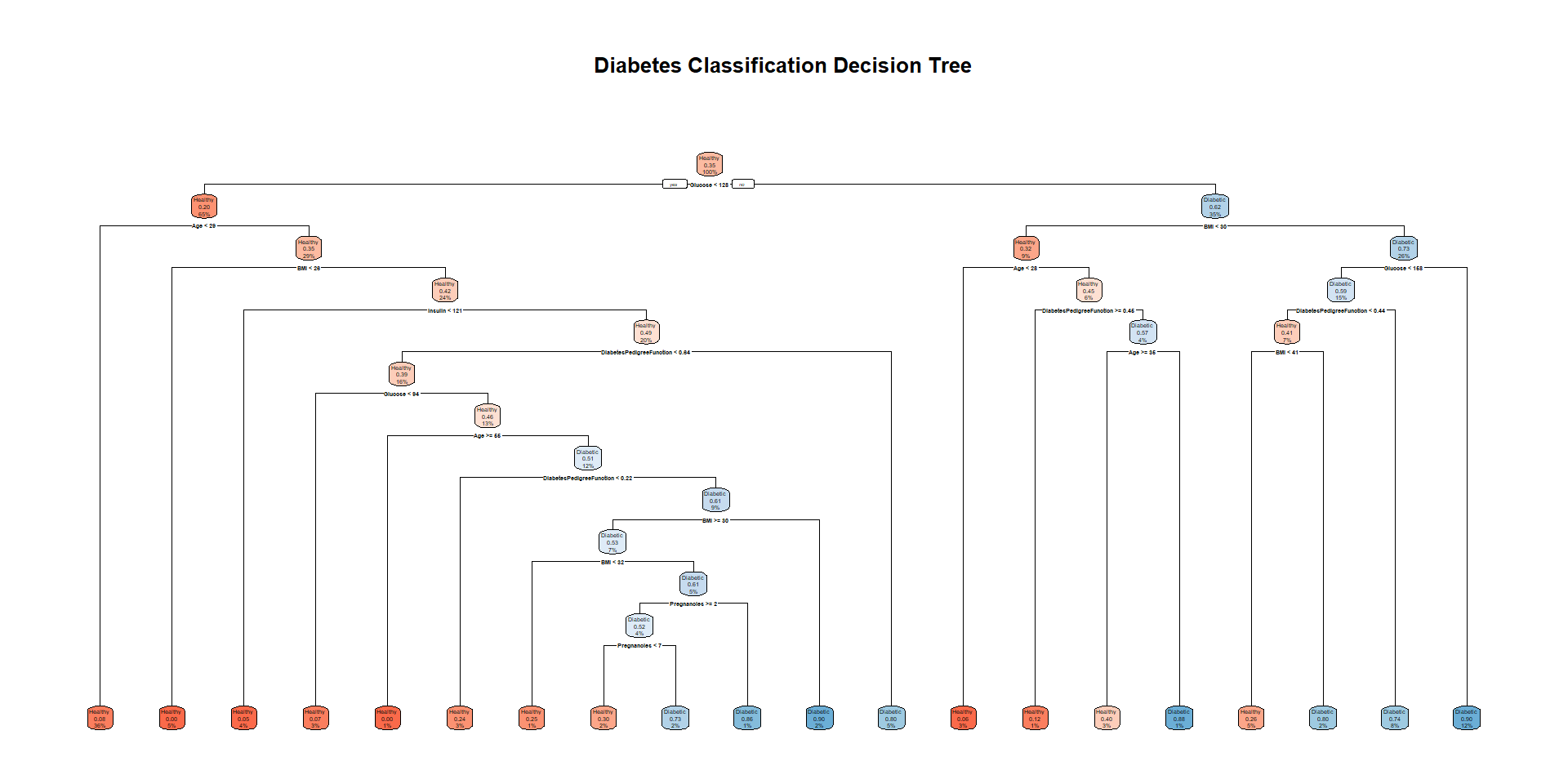
Feature Importance
# Extract variable importance
var_importance <- diabetes_tree$variable.importance
var_importance_df <- data.frame(
Variable = names(var_importance),
Importance = var_importance
)
# Plot variable importance
ggplot(var_importance_df, aes(x = reorder(Variable, Importance), y = Importance)) +
geom_bar(stat = "identity", fill = "steelblue") +
coord_flip() +
labs(x = "Variables", y = "Importance",
title = "Variable Importance in Diabetes Prediction") +
theme_minimal()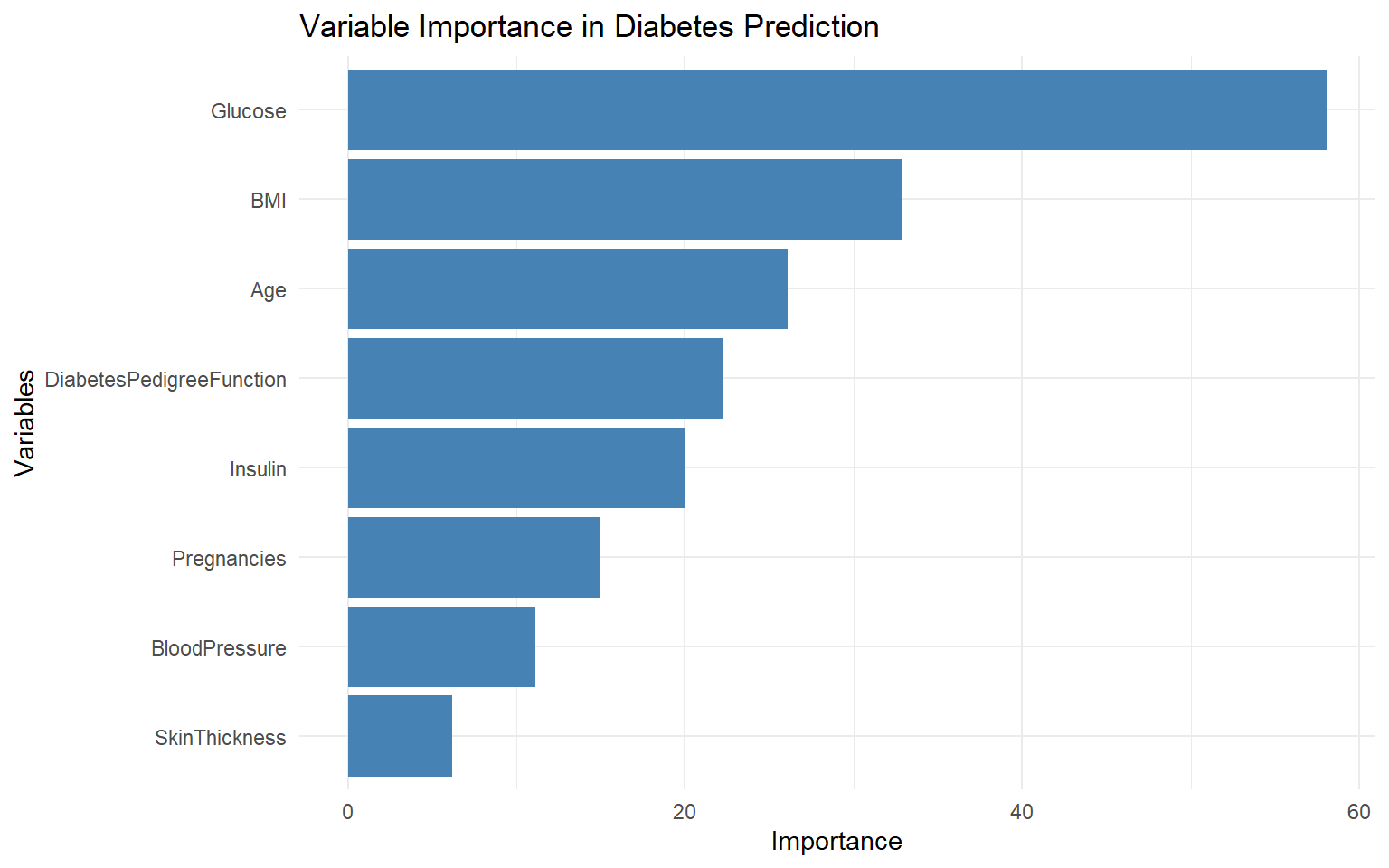
Hyperparameter Tuning
We can tune the complexity parameter (cp) to control tree growth:
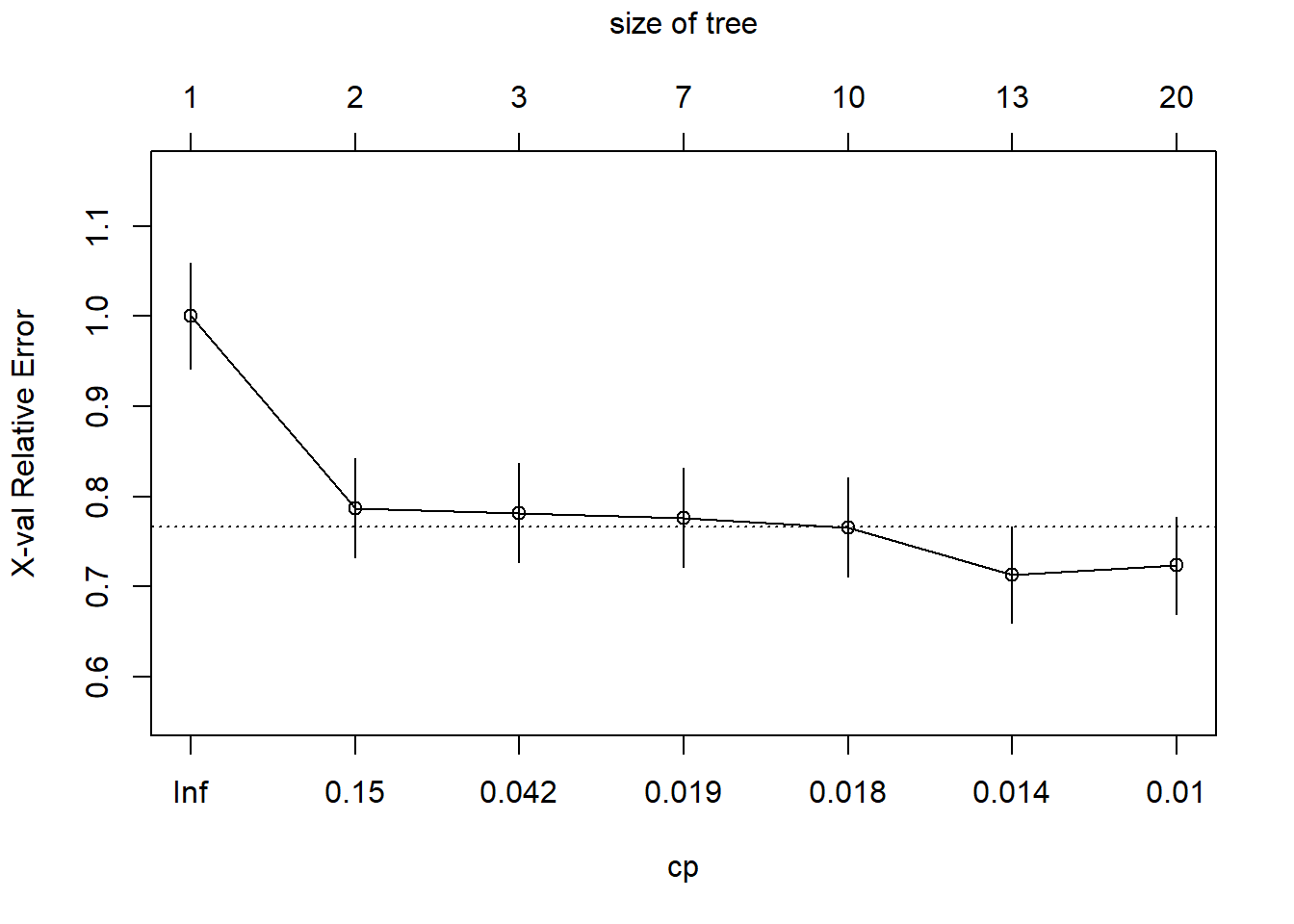
# Find optimal cp value
optimal_cp <- diabetes_tree$cptable[which.min(diabetes_tree$cptable[,"xerror"]),"CP"]
cat("Optimal CP value:", optimal_cp, "\n")Optimal CP value: 0.0106383 # Train model with optimal cp
pruned_tree <- prune(diabetes_tree, cp = optimal_cp)
# Plot pruned tree
rpart.plot(pruned_tree,
extra = 106,
box.palette = "RdBu",
fallen.leaves = TRUE,
main = "Pruned Diabetes Classification Tree")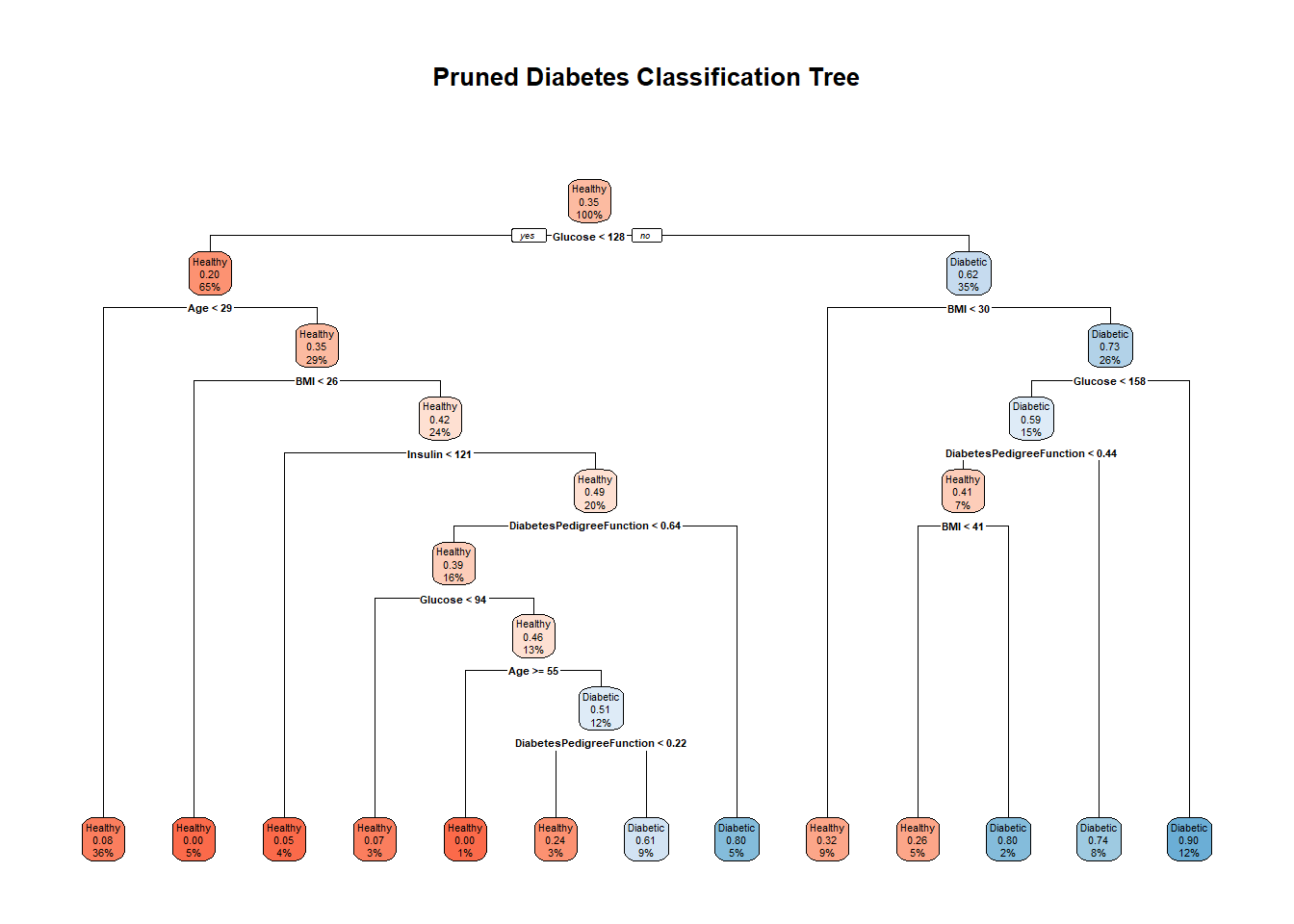
Ensemble Learning
Random Forests overcome many limitations of single decision trees through:
- Bootstrap Aggregation (Bagging): Training many trees on random subsets of data
- Feature Randomization: Considering only a subset of features at each split
- Voting/Averaging: Combining predictions from all trees
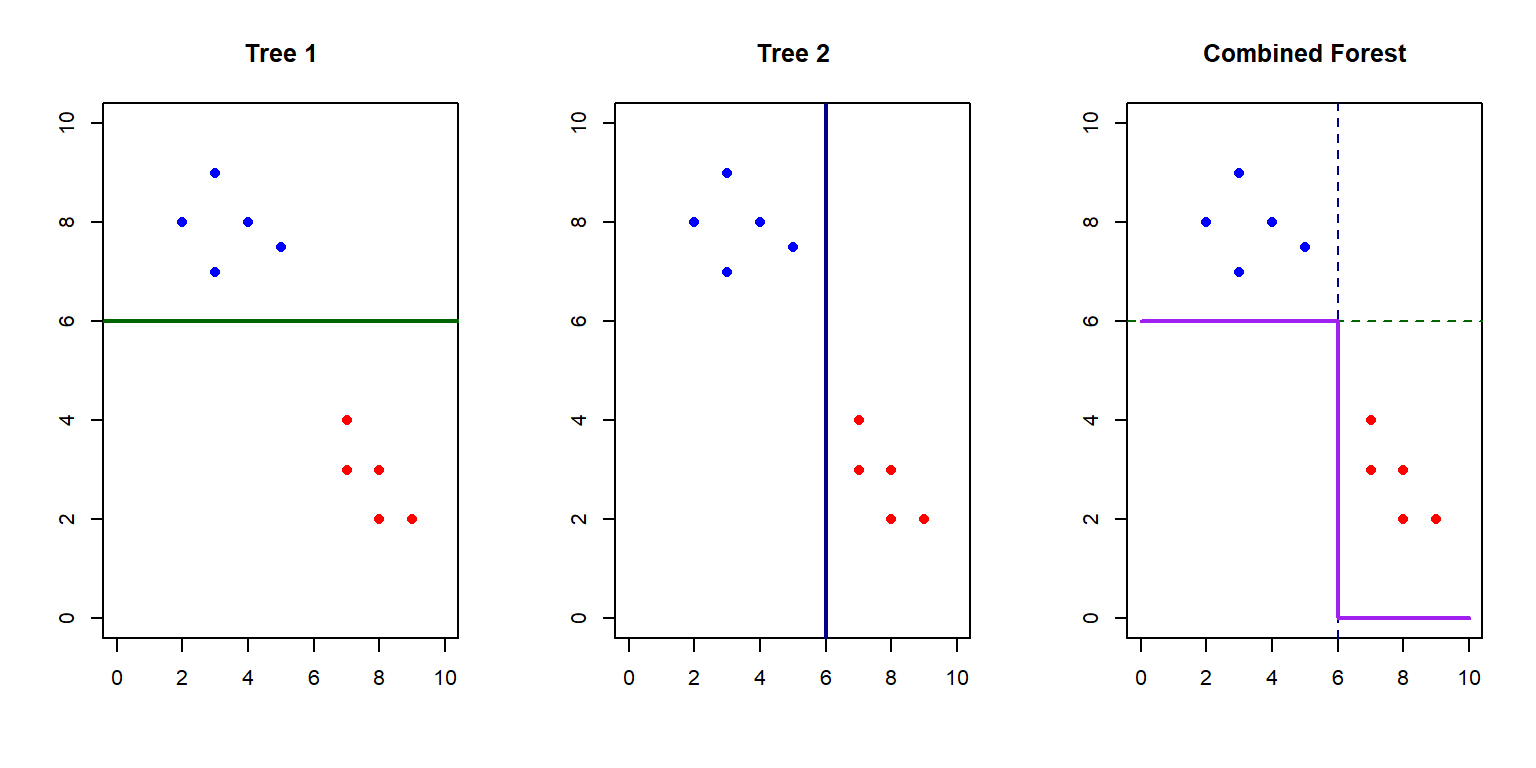
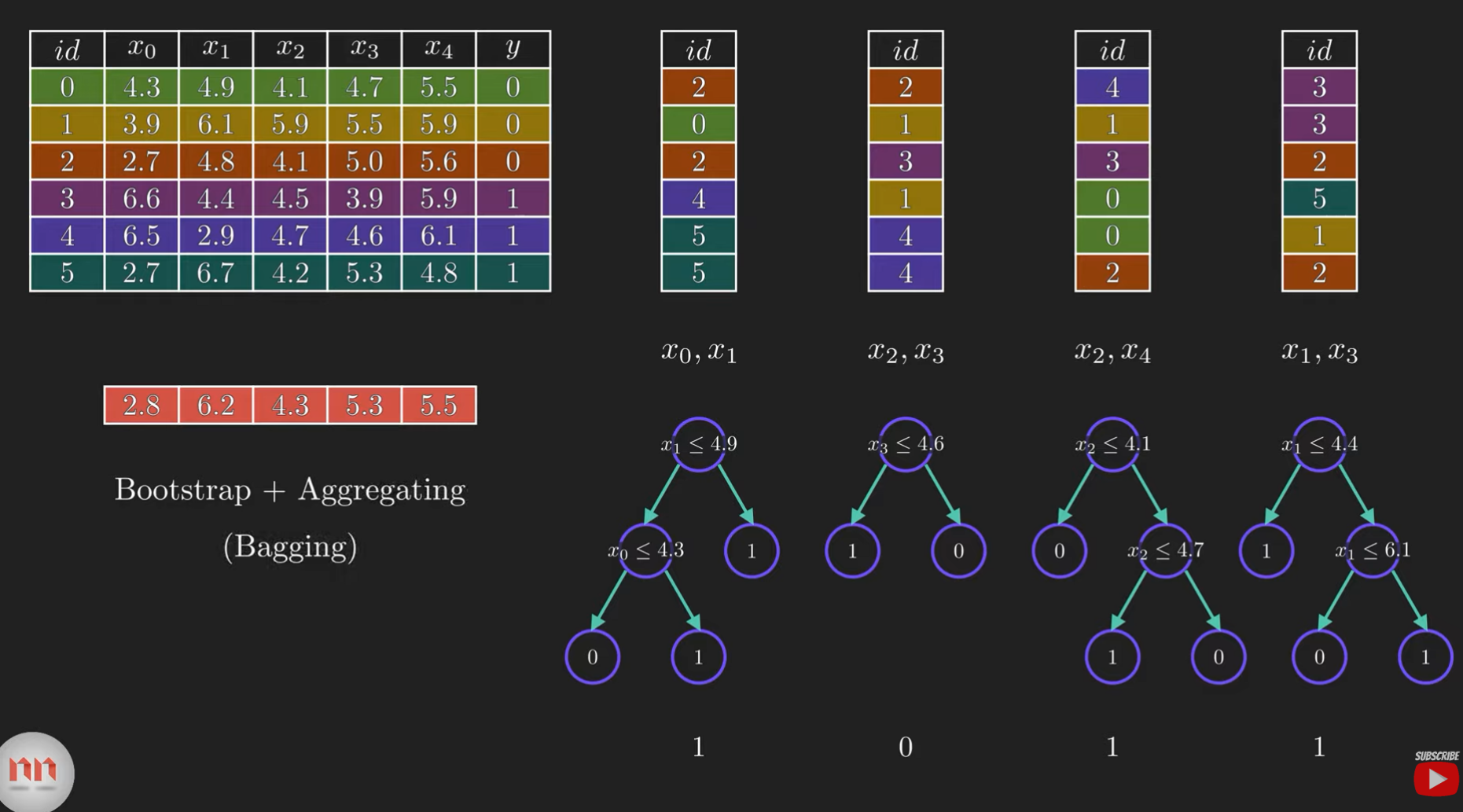
Random Forest Implementation
# Train Random Forest model
set.seed(123)
diabetes_rf <- randomForest(Outcome ~ .,
data = train_data,
ntree = 100, # Number of trees
mtry = sqrt(ncol(train_data)-1)) # Number of variables tried at each split
# Print the model
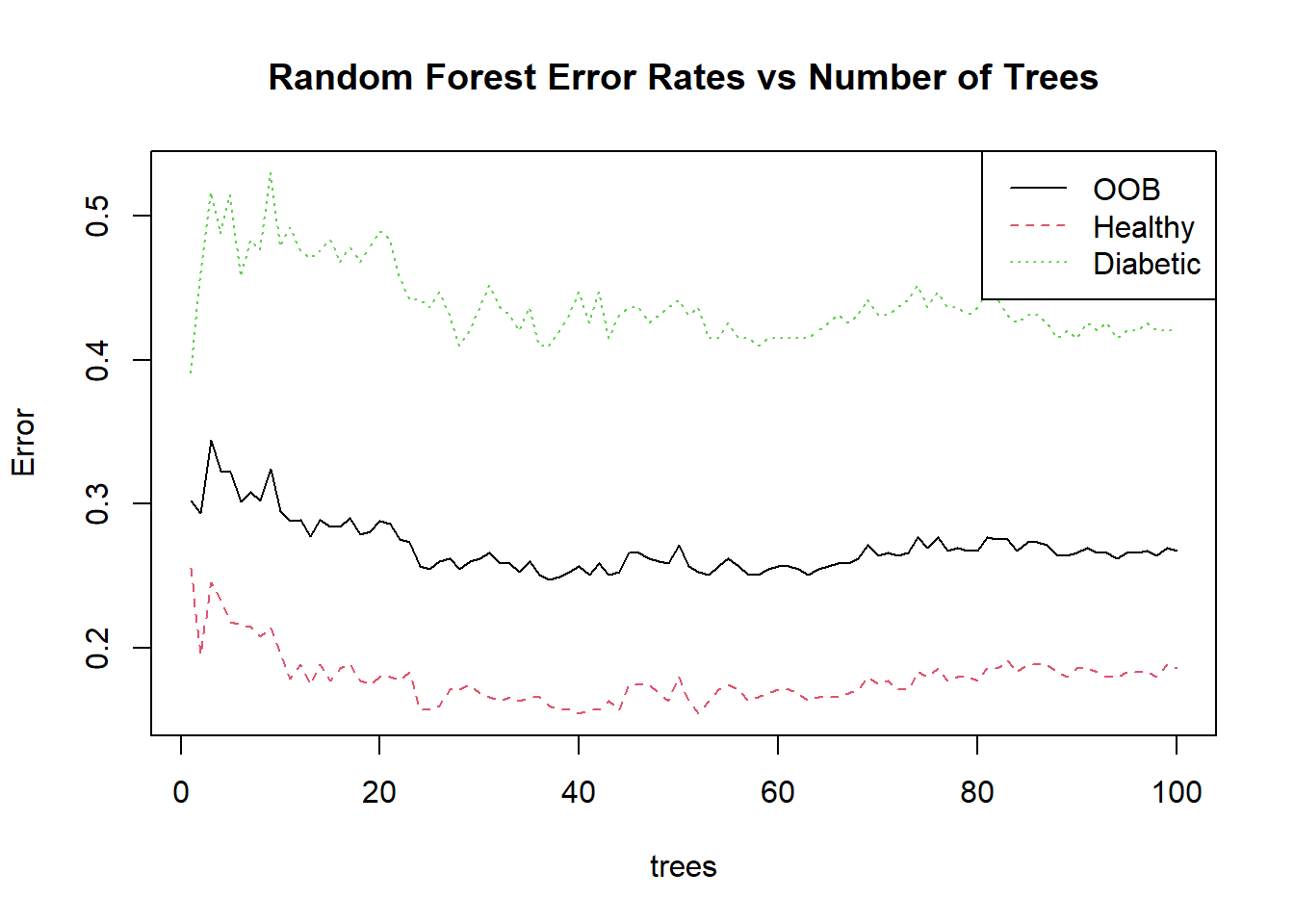
print(diabetes_rf)
Call:
randomForest(formula = Outcome ~ ., data = train_data, ntree = 100, mtry = sqrt(ncol(train_data) - 1))
Type of random forest: classification
Number of trees: 100
No. of variables tried at each split: 3
OOB estimate of error rate: 26.77%
Confusion matrix:
Healthy Diabetic class.error
Healthy 285 65 0.1857143
Diabetic 79 109 0.4202128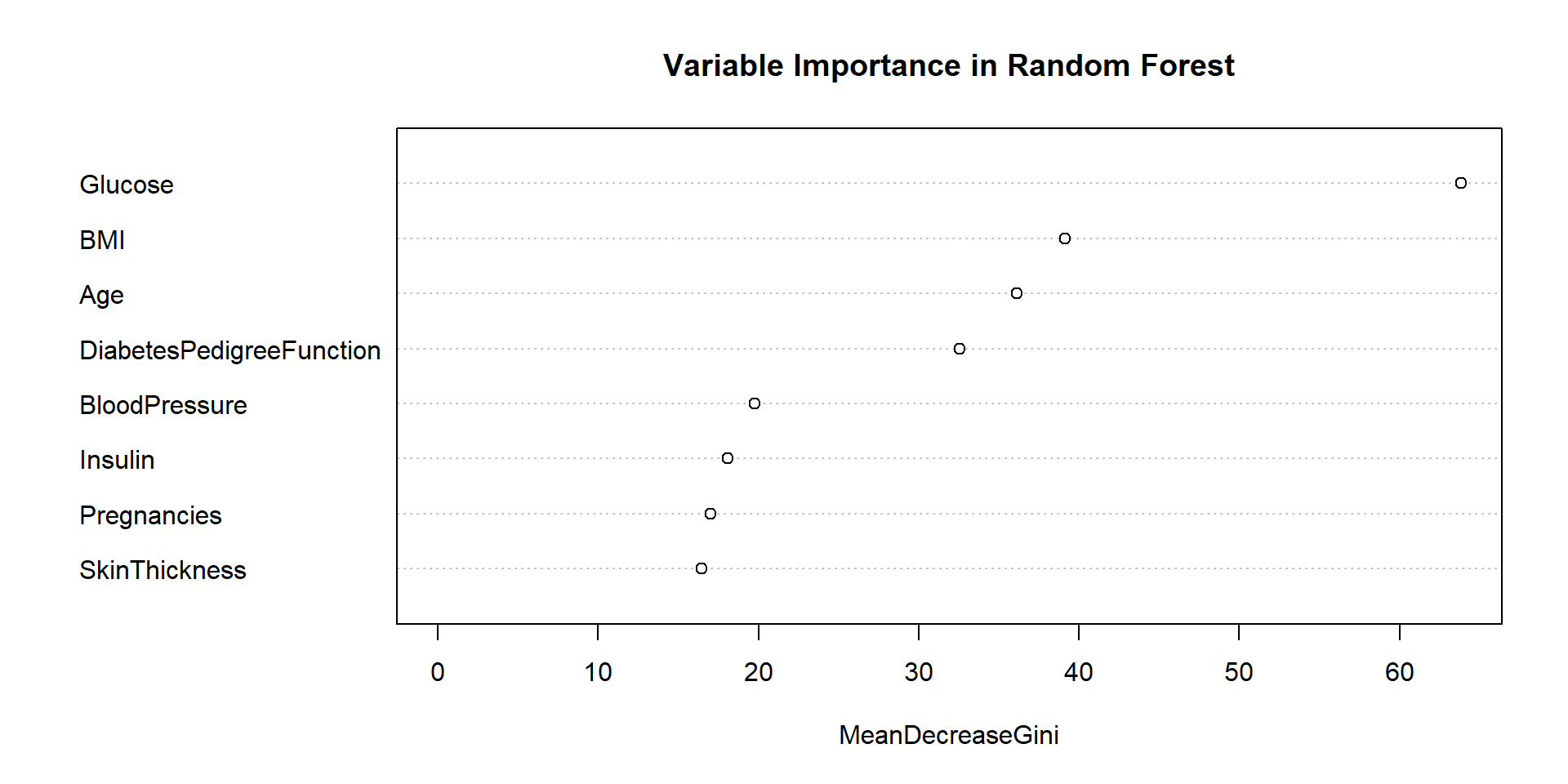
Out-of-Bag Error Estimation
One unique advantage of Random Forests is out-of-bag (OOB) error estimation:
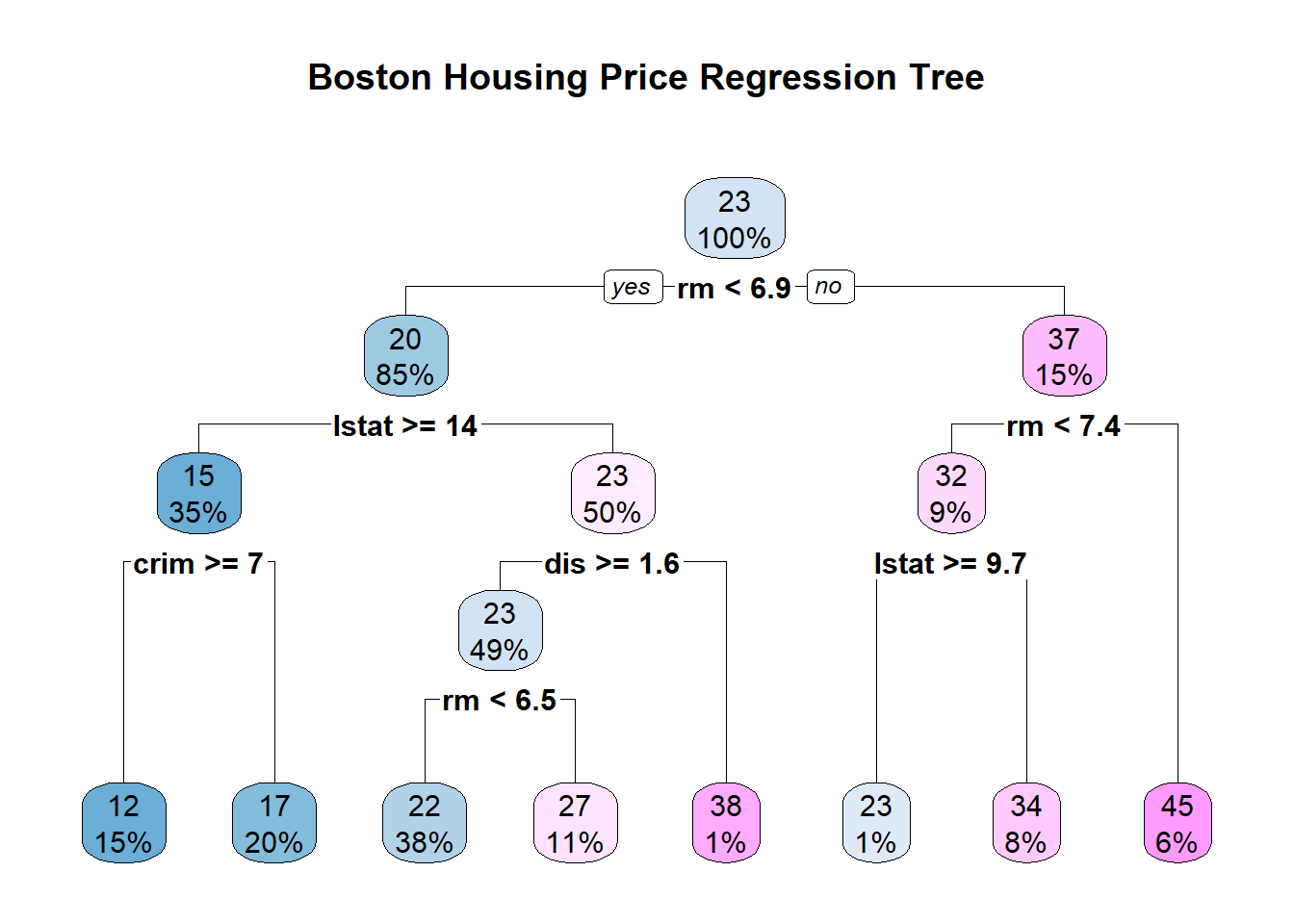
Regression Trees
Decision trees can also be used for regression problems: